

搜索网站、位置和人员



电话: +86-(0)571-85279887 工学院
如今的大数据时代充满了高维数据——超过二维,无法直接在平面中表示的数据。高维数据来自许多方面,如医疗记录、环境监测、商业市场、社交网络等。以汽车数据为例,需要从马力、单位燃油续航里程和产地等属性进行综合考虑。但是,如果不借助高维数据可视化技术,很难直观地理解高维数据中不同属性之间的关系或矛盾。对这些高维数据进行分析和利用,可以为人类生活和生产带来巨大的便利。
近日,西湖大学工学院成生辉课题组的数据可视化研究成果“Graphical Enhancements for Effective Exemplar Identification in Contextual Data Visualizations”被IEEE Transactions on Visualization and Computer Graphics(TVCG)录用,西湖大学工学院青年研究员成生辉为通讯作者。TVCG是计算机可视化领域的顶级期刊,被中国计算机学会(CCF)列为A类期刊。此工作通过可视化的方式,在二维空间中还原了高维数据中的信息,并采用可视化的增强手段,帮助用户快速地进行样本识别和组合选择。

论文地址:https://ieeexplore.ieee.org/document/9765327
高维数据可视化分析
可视化分析致力于从原始数据中挖掘关系并将这些关系可视化,从而协助人类探索和利用各种复杂的数据。高维数据的可视化分析,是可视化领域一个经典的疑难问题。本文创造性地运用一种投影策略——数据可解释性映射(Data Context Map),在二维空间内传达高维空间中的信息,并通过不同的可视化增强方案,来对高维空间中的样本进行识别和选取。
数据可解释性映射是一种针对多属性的可视化方法,它能够让用户根据不同的特征识别样本。图1即是采用此方法帮助消费者选择理想汽车的例子。该图通过融合特征和样本可视化了不同的汽车及其对应的特征,从而帮助消费者选择理想的汽车。消费者可以根据马力,每加仑燃油所行英里数和原产地来选择适合自己的汽车。
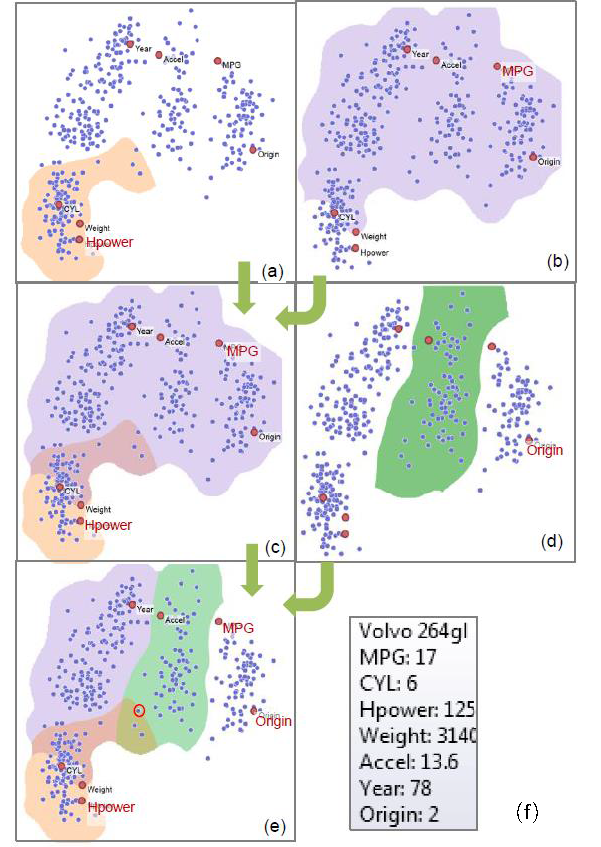
图1. 通过数据可视化选择理想的汽车,图中蓝色的点是不同的汽车,其它颜色的点对应不同的特征。(a) 马力(120~230),(b) 每加仑燃油所行英里数(15~46);(c) 为(a)和(b)组合而成;(d)原产地(欧洲);(e) 为(c)和(d)组合而成;(f)一个汽车数据的例子。
可视化地从具有高维特征的数据中选择样本组合
如何在高维数据中选择恰当的样本组合是一个关键问题。首先需要对高维数据进行二维映射并在映射中还原高维空间中的分辨信息,然后再进行样本组合选取。选择出的样本需要根据需求兼顾数据集中不同的属性。在现实生活的应用中,对于系统工程、投资银行、药物咨询、产品营销和许多其他领域,高维数据中的样本组合的选择显得非常重要。
基于数据可解释性映射,本文通过图形增强帮助用户更好地理解高维数据中的特征,从而更有效地选择样本组合。文章对三种不同的图形增强进行了研究,分别是ISO等高线、着色地形渲染和地势渲染,并将其与原本的数据可解释性映射显示进行了比较。使用Pareto优化在可视化界面生成了选择的样本组合。
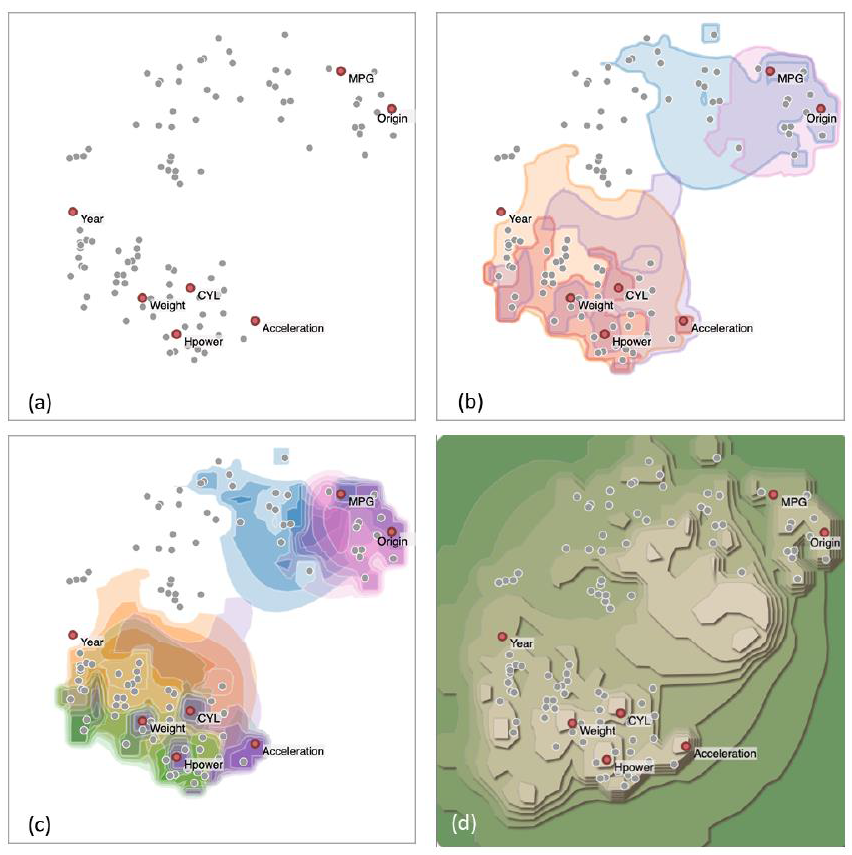
图2. 在汽车数据集上的渲染结果。(a)数据可解释性映射;(b)ISO等高线;(c)着色地形渲染;(d) 地势渲染。
以图1中的汽车数据集为例,图2显示了三种图形增强的对应渲染结果,并与原本的数据可解释性映射显示进行了比较。其中(a)是原始的数据可解释性映射。(b)是基于ISO等高线的渲染。在这种可视化中,对属性不同的约束由不同彩色区域表示。每个轮廓都是一个可视化的特定的属性约束。分析人员可以了解各种约束如何在空间上分布,并查看每个样本点在区域中满足哪些约束。用户可以通过滑块调整ISO轮廓来收紧或放松属性约束。但是这种方法无法显示属性的局部敏感性。(c)是基于着色地形图的渲染。它显示了属性不同程度的ISO等值线。这样可以显示不同属性的局部敏感性,但在颜色过多时容易产生歧义。(d)是通过2.5D技术进行的地势渲染,这样可以避免由于过多颜色产生的歧义,并且在一定程度上保持了数据的可解释性。用户可以根据实际需求选择不同的渲染方案。
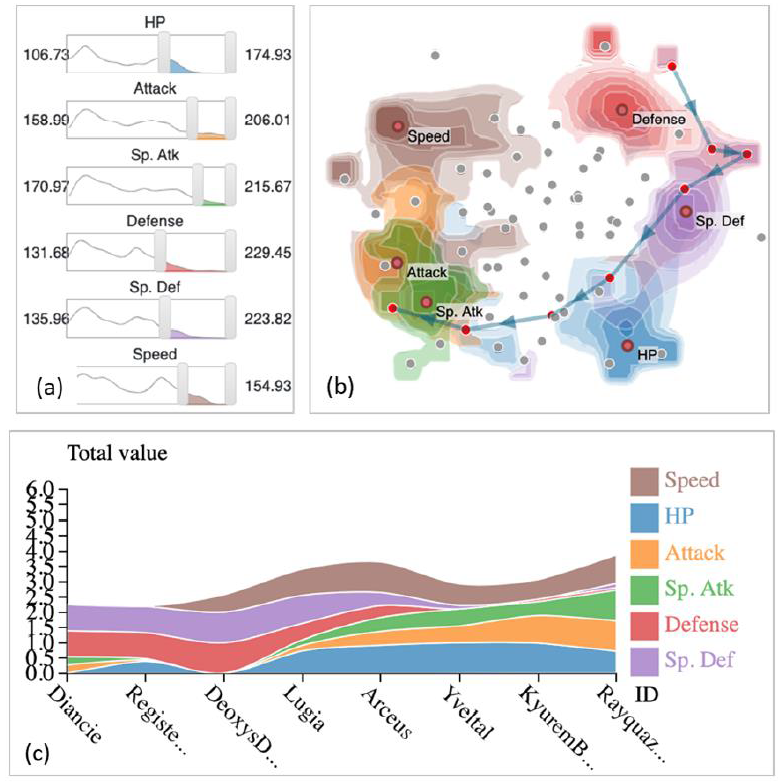
图3. 用户界面组件,这里显示的是Pokemon数据集。(a) 值滑块对应6个属性;(b)这6个属性的着色地形图,带有8个用户标记的示例,通过最短路径连接;(c)带有6个属性和8个示例的堆叠图。
不同的图像增强在用户界面是可调的,从而帮助用户选择出满足不同属性值的样本组合。图3 基于Pokemon数据和ISO等高线的渲染展示了用户界面的元素。(a)是值滑块,这些值滑块通过连续直方图进行调整,以告知用户在所选间隔内有多少数据实例。(b)显示了某个用户在值着色地形图中选择的Pokemon。选择后,使用最短路径算法自动连接这些实例。(c)可视化地显示了在这条路径上不同的属性是如何变化的。
基于上述的框架,用户可以通过选择不同的图形增强在数据可解释性映射的基础上更好地理解数据特征和样本之间的关系,从而有效地选择样本。为了证明这个框架的有效性,进行了如下的示例研究。
示例研究
为了展示文中所提出的样本选择方式是否能满足不同用户的需求,基于用户选择进行了示例研究。
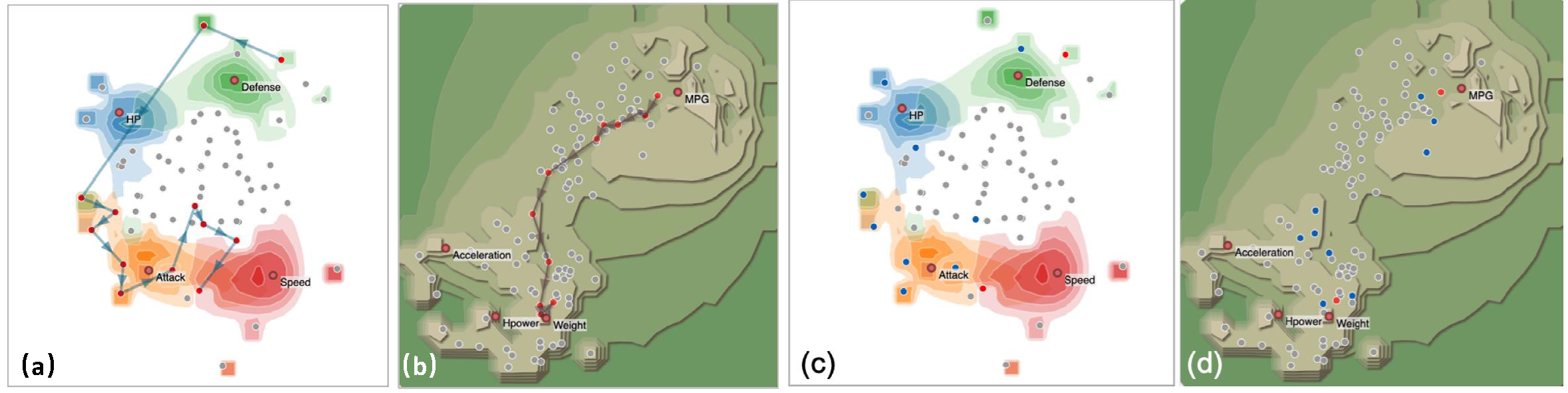
图4. 用户研究的四个场景,每个场景都使用一个图形增强进行渲染。(a)使用Pokemon数据集的Pokemon玩家;(b)使用汽车数据集的租车代理经理;(c)和(d)显示了被用户选择的样本。其中,两个红点代表两个终端示例,而蓝点代表用户选择。
图4是不同的渲染针对不同用户的研究结果。在第一个场景中,参与者被要求扮演一个Pokemon玩家的角色。Pokemon集由65个Pokemon组成。参与者被告知,玩家对四个属性评价很高,即攻击、防御、生命和速度。从给定的可解释映射中,参与者通常会观察到,没有Pokemon能够同时拥有高的不同的属性值。因此参与者需要捕捉一系列的Pokemon,从而形成能够互补的Pokemon阵容。Pareto路径算法的选择Pokemon的结果如(a)所示。
在第二个场景中,参与者被告知一家租车公司最多可容纳12辆汽车,并被要求提供一个能让大多数潜在租车者满意的汽车组合。共有100辆汽车可供选择,参与者可以选择以下四个标准:加速度、马力、MPG和重量。可解释性映射显示,马力与每加仑燃油所行英里数呈负相关,因此将这两个属性放在映射的两端。加速度、重量与马力呈正相关,因此将它们映射到同一区域。Pareto路径算法的选择结果如(b)所示。这两个场景的用户选择分别在(c)和(d)中展现。可以看到用户所选择的样本在Pareto路径算法所求得的路径上或者周围。
该研究的主要贡献如下:
第一,基于可解释数据映射,将高维数据映射到了二维空间,还原了高维空间中的分辨信息。在此基础上,增加了一组图像渲染功能以更好地解释数据,同时帮助用户选出符合设定目标的样本组合。
第二,进行了用户界面开发,帮助用户快捷地调节所需要样本的属性值,从而高效地选择样本。
第三,提出了一种Pareto算法,以自动选出尽可能符合设定目标的样本组合,并通过示例研究证明了所提出算法能够满足不同的用户需求。
最新资讯
大学新闻
学术研究
学术研究
学术研究
学术研究














