

搜索网站、位置和人员



电话: +86-(0)571-86982287 工学院
近日,国际学术会议CVPR 2023公布了论文接收结果。西湖大学工学院人工智能与数据科学研究领域李子青课题组、刘沛东课题组、王东林课题组、杨林课题组和袁鑫课题组共6项研究成果被录用。
CVPR(IEEE / CVF Computer Vision and Pattern Recognition Conference),即“国际计算机视觉与模式识别会议”,是由IEEE举办的计算机视觉和模式识别领域的顶级会议,在世界范围内每年召开一次,并被中国计算机学会(CCF)推荐为计算机学科领域A类国际会议。本届会议录用率为25.78%。
一种全新的对比多模态变换范式CVT-SLR
CVT-SLR: Contrastive Visual-Textual Transformation with Variational Alignment
(本文被CVPR官方评选为Highlight,录用率为2.57%)
郑蒋滨
李子青实验室博士生
【背景知识】
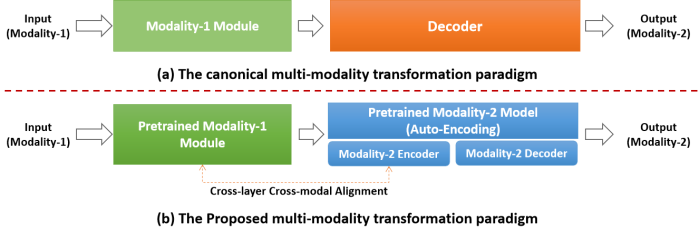
图1:传统的多模态学习范式和提出的多模态学习范式的比较示意图
多模态学习是人工智能领域的一个重要课题,涉及文本、图像、视频、音频等不同模态之间的深度转换和交互。然而,目前多模态学习的主要瓶颈之一是缺乏足够的训练数据。为解决这个问题,迁移学习成为提升多模态学习性能的重要手段之一。
在通用的多模态学习范式中(如图1a),通过编码器-解码器实现从源端(模态1)到目标端(模态2)的映射转换。然而,由于范式的限制,目标端模态往往无法有效地利用预训练模型的先验知识,只有源端模态可以受益于先验知识的应用。观察到这种现象,本文作者提出了一种新颖的多模态学习范式(CVT),在多模态框架中引入了目标端模态的预训练先验知识(如图1b)。
为验证这种新的范式,作者在手语识别(Sign Language Recognition, SLR)任务上进行实例化探索。SLR是典型且天然的跨模态任务,旨在将手语(视觉模态)转换为文本注释(文本模态)。然而,由于手语本身的复杂性和标注数据的极小规模,SLR极具挑战性。因此,作者使用所提出的多模态学习范式适配于SLR任务,引进了对比视觉-文本转换的SLR架构CVT-SLR,首次将预训练的语言模型和视觉模型同时应用至手语跨模态框架,并取得了优异的表现。
值得一提的是,目前该多模态学习范式已被成功推广至蛋白质设计、计算免疫等AI在生命科学的应用中,可以帮助提升性能并加速科学研究的进展。
【技术介绍】
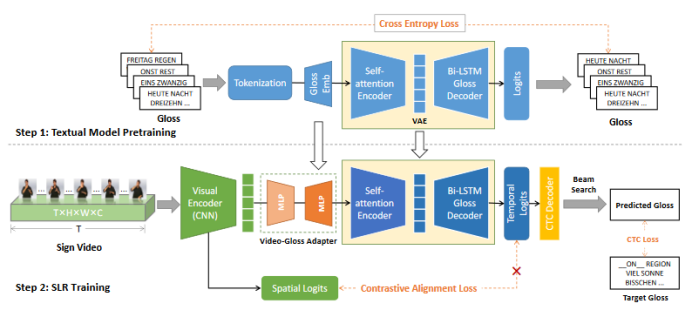
图2:CVT-SLR训练管线的示意图
在这项工作中,作者提出了一种名为CVT-SLR的新颖架构,用于解决手语识别(SLR)任务,并充分利用视觉和语言模态的预训练知识。CVT-SLR框架可以分为两个主要步骤,如图2所示。
第一步,是通过变分自动编码器(Variational Autoencoder, VAE)网络对文本模态进行预训练。VAE采用了完整的编码器-解码器架构,并通过无监督的方式构建了预训练的语境知识。由于自编码器的特殊形式,VAE能够保持输入和输出模态之间的一致性,从而实现隐性的跨模态对齐。这样的预训练过程引入了完整的预训练语言知识,并为后续任务提供了有用的先验信息。
第二步,将现有的视觉模块(通常是在Kinetics/ImageNet上训练而来的公开可用的CNN)和来自第一步预训练的文本模块转移到CVT-SLR框架中。为实现这种迁移,作者引入了一个称为Video-Gloss Adapter的桥接模块,其本质是一个多层感知机(MLP)层,用于将两个不同模态的预训练模块连接起来。此外,受先前跨模态学习和对比学习的启发,作者设计了一种内部跨层的跨模态对比对齐算法,其专注于正、负样本的构造,以显式地加强两个模态编码器的一致性约束,如图2中的Contrastive Alignment Loss所示。
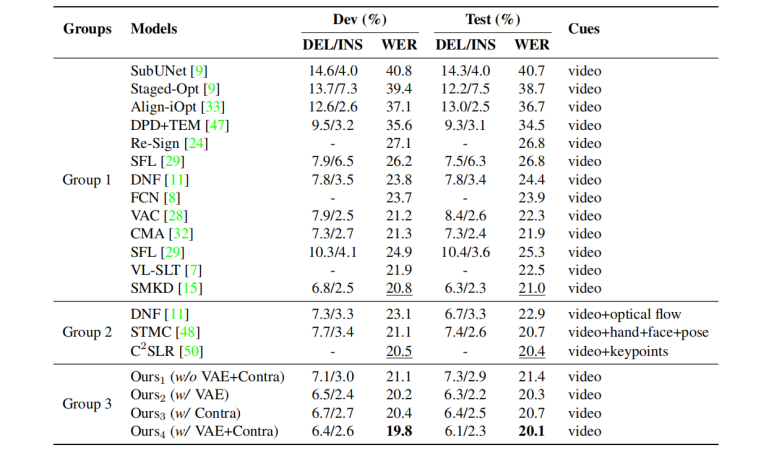
表1:(主实验)CVT-SLR和基线模型在PHOENIX-14数据集上的比较结果。WER和DEL/INS指标越低越好。每组的最佳结果和SOTA基线分别被标记为粗体和下划线
表1展示了CVT-SLR和基线模型的在流行的SLR数据集PHOENIX-2014上进行主要实验比较。实验结果表明,CVT-SLR不仅优于现有的其他单线索(输入仅手语视频)基线方法,甚至优于多线索(输入包括视频和其他辅助信息)的最先进方法。这一结果验证了在多模态框架中有效引入先验的源端和目标端模态知识能够改善跨模态任务的性能。通过消融研究和定性分析,作者还进一步验证了引入预训练的语言知识和一致性约束机制的合理性。
论文链接:https://arxiv.org/abs/2303.05725
代码链接:https://github.com/binbinjiang/CVT-SLR
利用时空注意力单元实现高效时空预测学习
Temporal Attention Unit: Towards Efficient Spatiotemporal Predictive Learning
谭铖、高张阳
李子青实验室2021、2020级博士生
【背景知识】
时空预测学习是一种通过学习历史帧来预测未来帧的自监督学习范式,可以利用海量的无标注视频数据学习丰富的视觉信息,在气象预测、交通流量预测、人体姿势变化估计等领域有着广泛的应用场景。时空预测学习需要考虑视频中的空间相关性和时间演变规律,这是一项具有挑战性的任务。传统的方法主要基于循环神经网络来建模时间依赖关系,但是RNN有着计算效率低、难以捕捉长期依赖、容易出现梯度消失或爆炸等缺点。因此,如何设计一个高效、准确、稳定的时空预测学习模型,是一个亟待解决的问题。为了解决这个问题,我们首先研究现有的方法,并提出时空预测学习的通用框架,如图1所示。
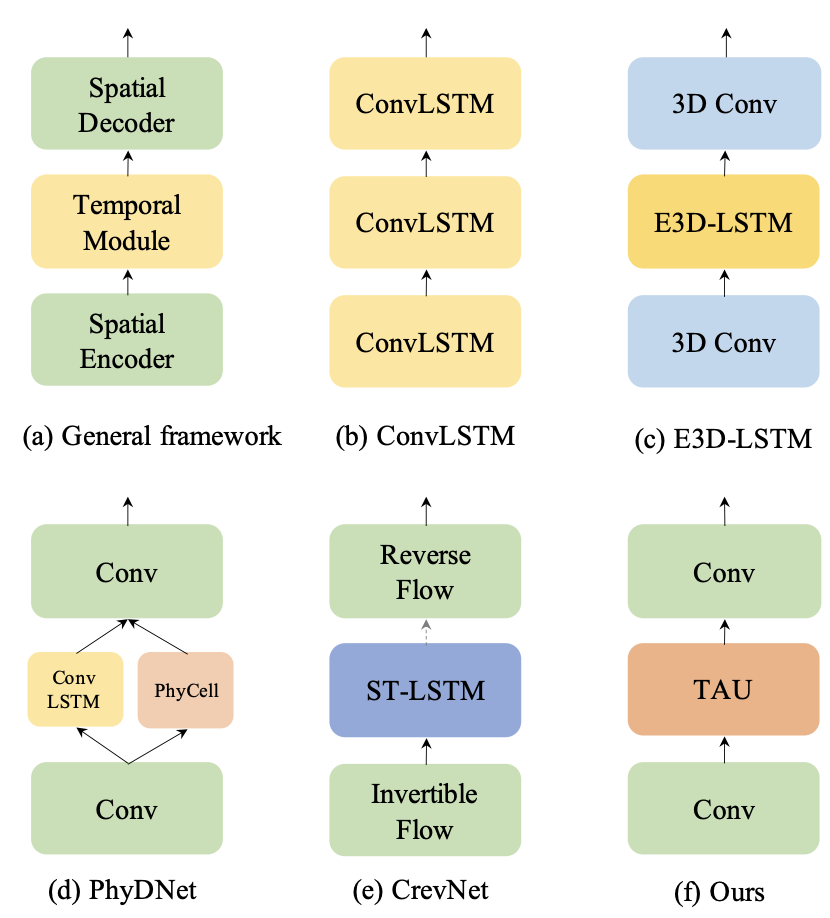
图1:时空预测学习的通用框架
在该框架中,空间编码器和解码器捕捉帧内特征,中间的时序模块捕捉帧间相关。尽管主流方法采用循环单元来捕捉长期时序依赖关系,但由于其非并行架构,计算效率较低。为了并行化时序模块,提出了一种新颖的时空预测学习模型,名为时空注意力单元(Temporal Attention Unit, TAU),实现了高效的时空预测学习。
【技术介绍】
如图2所示,TAU模型不使用循环神经网络,而是使用注意力机制来并行化地处理时间演变。TAU模型将时空注意力分解为两个部分:帧内静态注意力和帧间动态注意力。帧内静态注意力使用小核心深度卷积和扩张卷积来实现大感受野,从而捕捉帧内的长距离依赖关系。帧间动态注意力使用通道间注意力的方式来学习不同帧之间的通道权重,从而捕捉帧间的变化趋势。此外,我们还提出了一种新颖的差分散度正则化方法,用于优化时空预测学习的损失函数。该方法同时考虑了帧内误差和帧间变化量。通过将预测帧和真实帧之间的差分转换为概率分布,并计算它们之间的KL散度,来强制模型学习到视频中固有的变化规律。
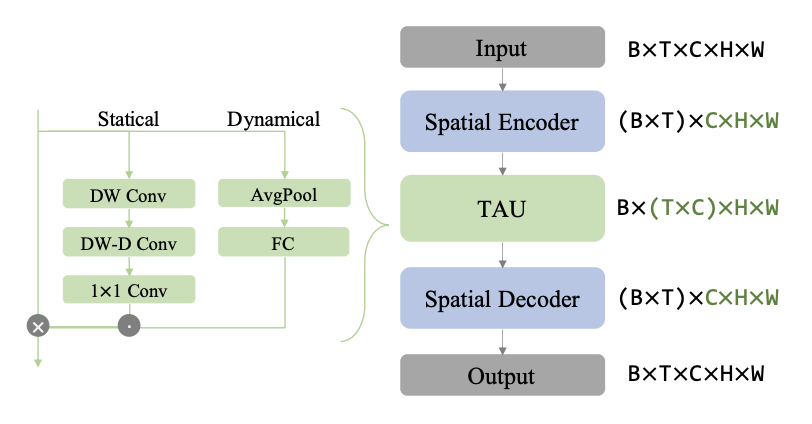
图2:模型结构图
我们的模型在多个数据集上都取得了优异的性能,超越了许多基于循环神经网络或其他复杂技术的方法。此外,我们的模型不仅可以提高视频生成质量,还可以提高计算效率和训练速度。如图3所示,收敛速度极快,50轮训练即可达到MSE 35.0的水准。在相同实验环境下,TAU模型在基准数据集上每个周期只需要2.5分钟,而此前的SOTA方法需要7到30分钟不等。
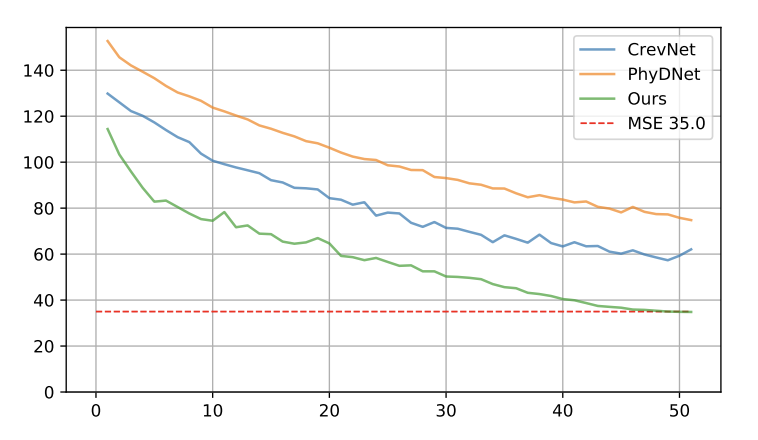
图3:模型收敛速度对比,绿色表示TAU模型
TAU模型现已经开源在我们的时空预测标准库OpenSTL中,见下方链接。OpenSTL是一个包含了十余种时空预测算法的标准库,现已支持生成移动字符预测、交通流量预测、人体姿势变化估计、真实道路场景变化预测、全球气象预测等众多任务,提供了系统且完整的时空预测学习评估模式,欢迎大家体验交流。
论文链接:
代码链接:https://github.com/chengtan9907/OpenSTL
基于运动模糊图像的神经辐射场三维场景重建方法
BAD-NeRF: Bundle Adjusted Deblur Neural Radiance Fields
王朋
刘沛东实验室2022级博士生
【背景知识】
神经辐射场(Neural Radiance Fields,简称NeRF)是一种基于神经网络的三维场景表示方法,它可以从多个二维图像中恢复出高质量的三维场景。NeRF的核心思想是使用深度神经网络来表示场景中的每个点的辐射强度和密度,并通过体素渲染来生成图像。NeRF的训练数据通常需要多个清晰的二维图像以及图像对应的相机参数。NeRF在计算机图形学、计算机视觉和机器学习等领域都有着广泛的应用。
运动模糊是实际应用场景中最常见的降低图像质量的方式之一。运动模糊的图像会给现有的NeRF训练带来两个主要挑战:(1)NeRF通常假设训练的图像是清晰的(即无限小的曝光时间),因此运动模糊的图像违反了这一假设;(2)训练NeRF通常需要精确的相机参数,然而,仅从模糊图像中获得精确的位姿是困难的,因为模糊图像通常对曝光时间内的相机运动轨迹信息进行编码。结合这两个因素,使用运动模糊的图像将会进一步降低NeRF的性能。
【技术介绍】
本文提出BAD-NeRF,该模型将运动模糊图像的物理形成过程集成到NeRF的训练中,流程图如图1所示。在训练阶段,NeRF的网络权重和相机运动轨迹被联合优化。我们用曝光时间开始和结束时的两个相机位置以及SE(3)空间中的运动模型来表示每个图像的运动轨迹。曝光时间内的中间相机位置可以通过在SE(3)空间中插值得到。然后,我们可以遵循运动模糊图像的真实物理图像生成模型来合成模糊图像。NeRF和相机运动轨迹即可通过最小化合成模糊图像和真实模糊图像之间的差异来估计。
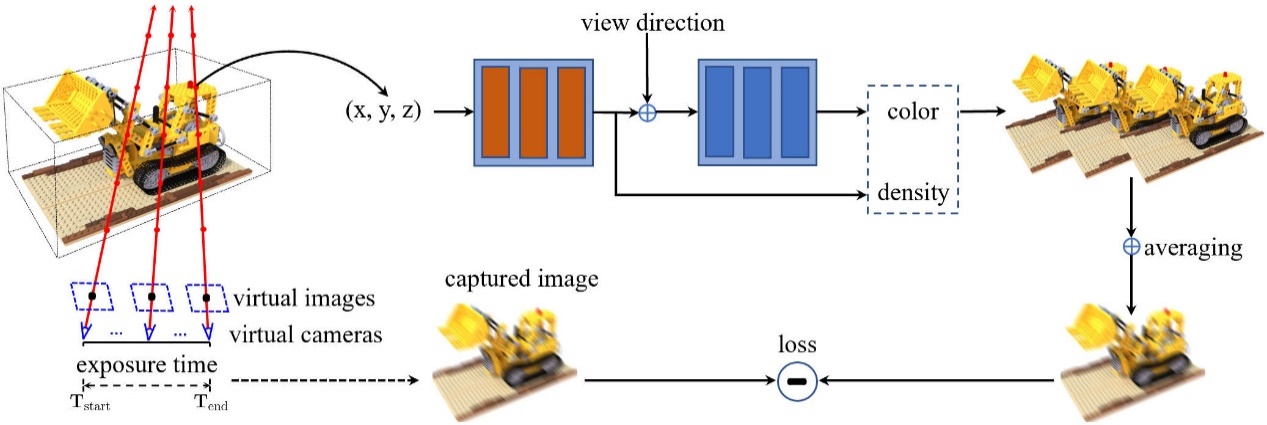
图1:BAD-NeRF训练流程图
大量的实验证明,BAD-NeRF能够从运动模糊的图像中恢复出清晰的三维场景,同时也能够准确地估计相机的运动轨迹。在相同的实验设置下,BAD-NeRF能够得到最好的实验结果,如图2所示。

图2:BAD-NeRF和其它去模糊方法的性能对比
论文链接:
代码链接:
https://github.com/WU-CVGL/BAD-NeRF
用于跨模态检索的文本-视频协作提示学习
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
黄思腾
王东林实验室2019级博士生
【背景知识】
在哔哩哔哩等视频网站寻找我们感兴趣的视频时,我们会在搜索框中输入文字来描述想看的内容。依靠强大的文本视频检索技术,视频网站能够将文本和视频以内容相关度连接起来,从而快速地找到和这段查询文字内容最相关的视频并提供给我们。
近年来,大规模文本-图像预训练模型的火热发展也推动着文本视频检索技术的更新换代。从视频抽取几张视频帧作为静止图像后,文本-图像预训练模型可以计算这些图像和查询文字的内容相关度,并汇聚计算结果来作为视频和查询的相关度。为了让模型能够在我们自己的文本视频数据库中取得更好的检索效果,我们可以进一步用自己的文本-视频数据对预训练模型进行参数的更新,让模型学习新知识。
与常用的参数整体更新(我们称之为“全局微调”)策略相比,最新的趋势是只更新模型原有的部分参数,或者只更新新加入到模型的少量参数。这种被称为参数高效微调的策略能够在缓解模型在学习新知识时出现遗忘在预训练学习到的旧知识的情况,并同时大幅减少在微调中需要更新的参数量,以此减少模型训练和存储上的负担。
我们的研究首次从文本-视频跨模态协作的角度出发,为文本视频检索探索更好的参数高效微调方案。通过在处理文本和视频时加入精心设计的、可学习的提示,我们仅增加了少量需要更新的参数,就能够取得比全局微调和现有参数高效微调方法更好的检索性能。总结来说,我们提出了兼顾精度和效率的新方案,来将文本-图像预训练模型用于文本视频检索。
【技术介绍】
本文首先提出一种文本视频检索的微调基线方案VoP。VoP的原理结构如图1所示,在保持预训练模型参数冻结的同时,我们在文本编码器和视频编码器的每一层都加入可学习的提示。仅需要数量相当于预训练模型0.1% 的需要更新的参数,VoP的检索表现可以持平甚至超越现有的参数高效微调方案。
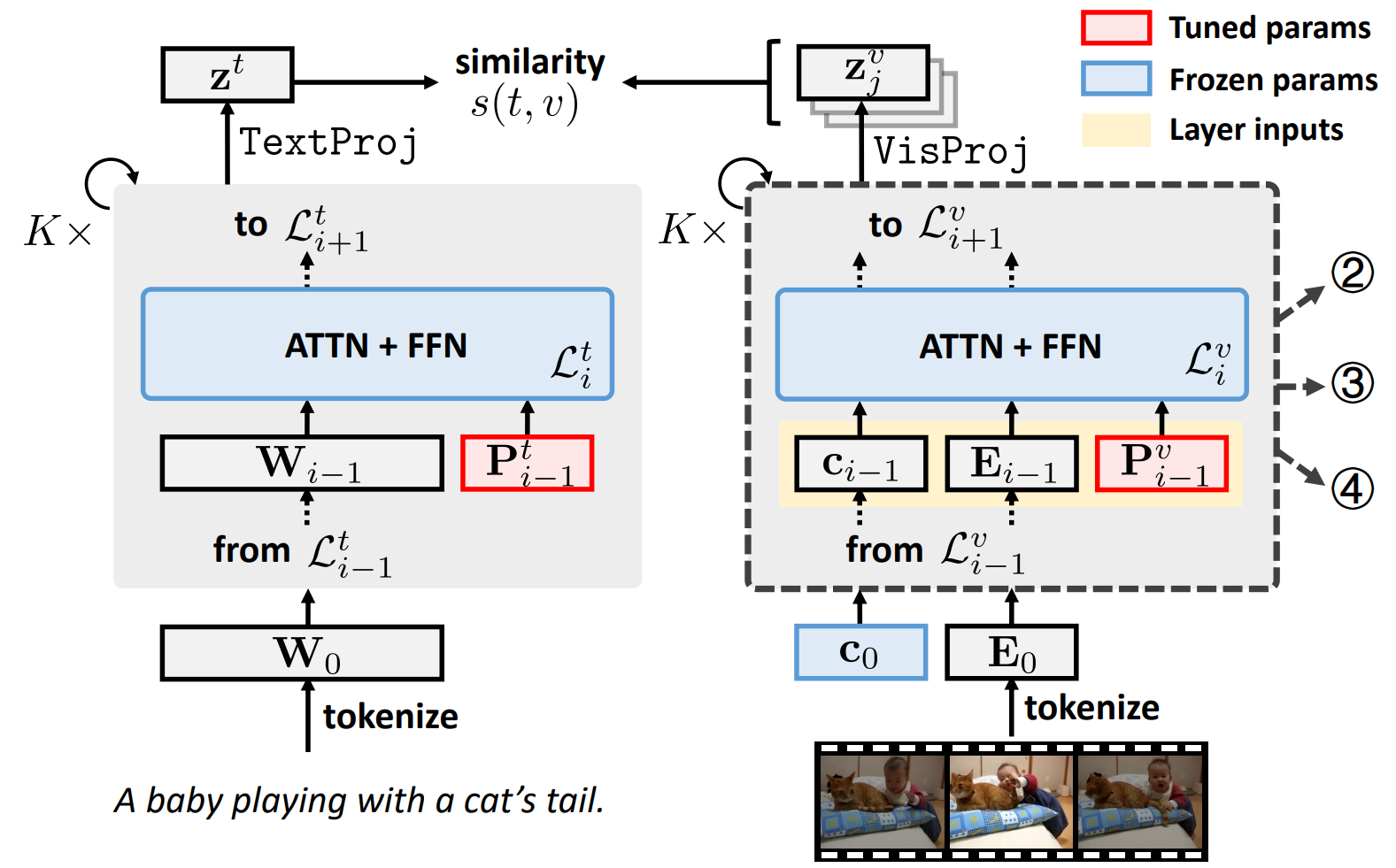
图1:VoP原理结构
为解决VoP依然将视频帧当作独立的图像、因此缺少对时序信息的建模的问题,我们继续为视频处理提出了三种视频特定的视觉提示,用于无缝替换VoP中采用的通用视觉提示。如图2所示,它们分别是:(1)位置特定的视频提示(VoPP),用于建模所有视频中处于同一相对位置的帧之间共享的信息;(2)上下文特定的视频提示(VoPC),用于将每一帧的上下文信息注入到该帧的内部建模中;(3)层功能特定的视频提示(VoPF),用于根据编码器层功能来选择性辅助帧内建模或者帧间建模。
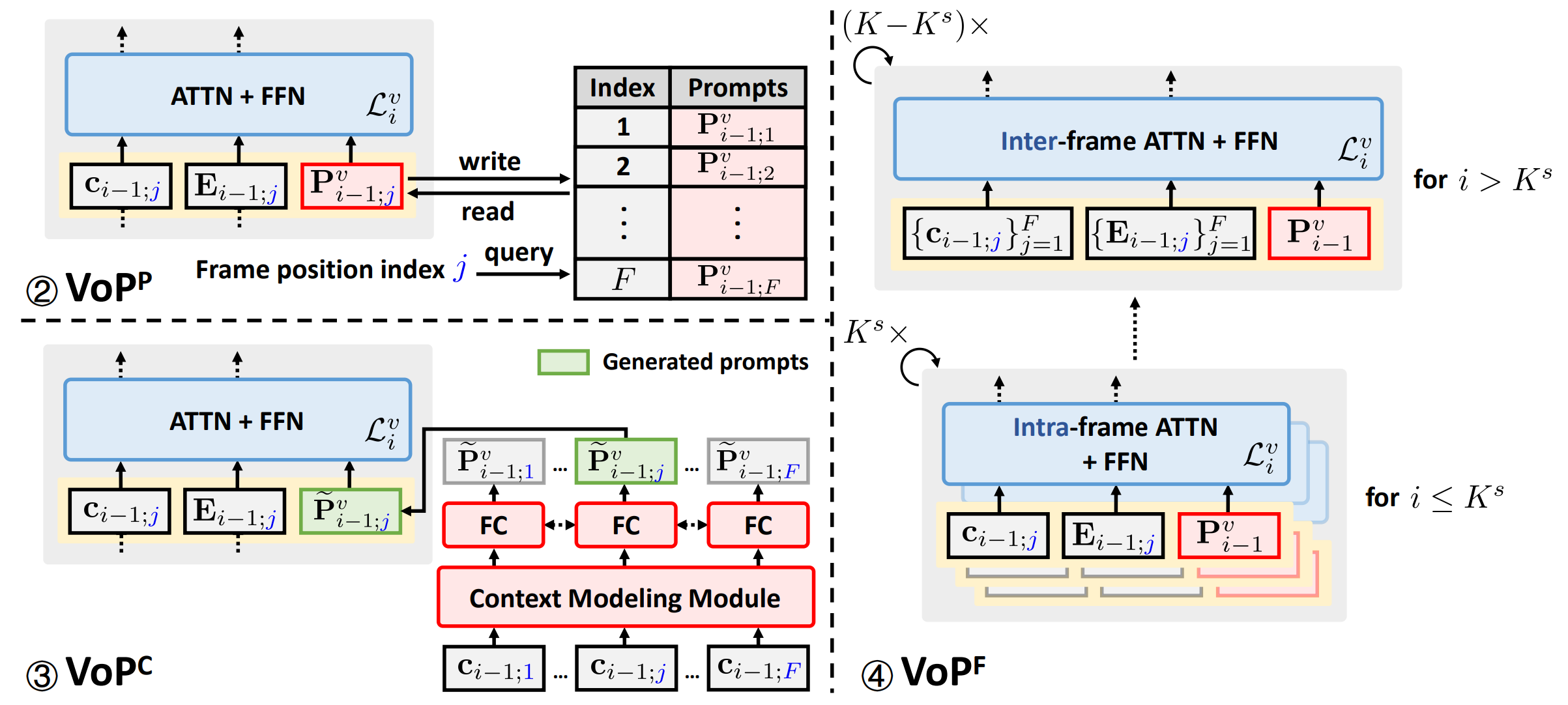
图2:三种视频特定提示的原理结构
如图3所示,在最常用的MSR-VTT-9k数据集上,我们提出的视频特定提示方案能够在限定参数量不变时将VoP的R@1(top-1召回率)提升3%。而组合视频特定提示方案能最多将VoP的R@1提升5%,从而只需要更新完全微调所需参数的11.78% 就能够比其R@1高2.9%,在检索表现和参数效率上都取得了显著的领先。
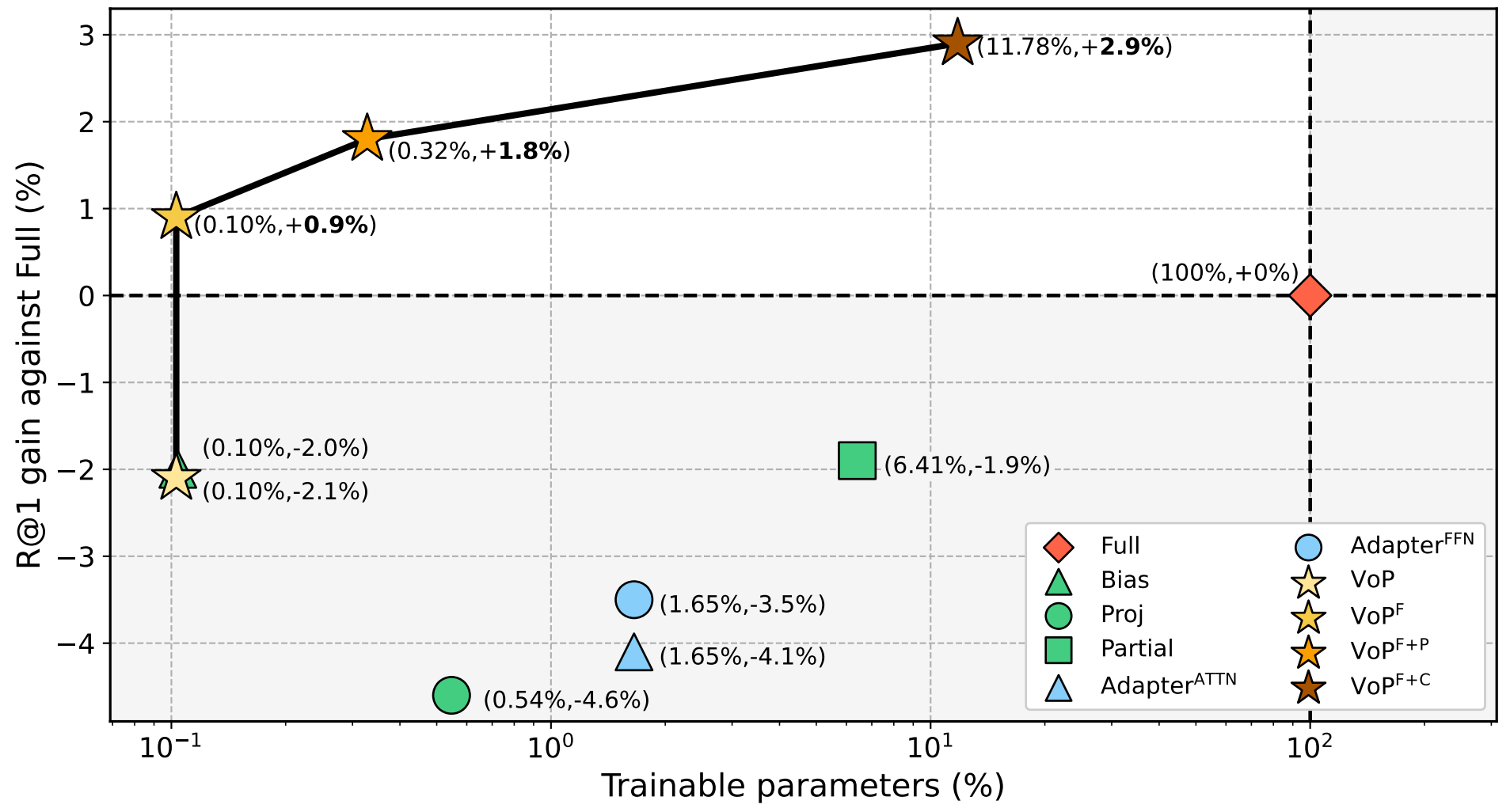
图3:MSR-VTT-9k数据集上各方案相比完全微调的检索表现增益及参数量对比
我们在图4中也展示我们提出的方案和完全微调(Full)以及已有的最好参数高效微调方案(Partial)的部分文本-视频检索结果。可以看到,我们的VoPF+C方案能够保留预训练知识(右上例子中理解日本文字和英语词汇),理解视频的整体含义(左下例子中能够预测是和神父交谈),并捕捉与具体概念的交互(右下例子中成功检索玩弄猫尾巴)。
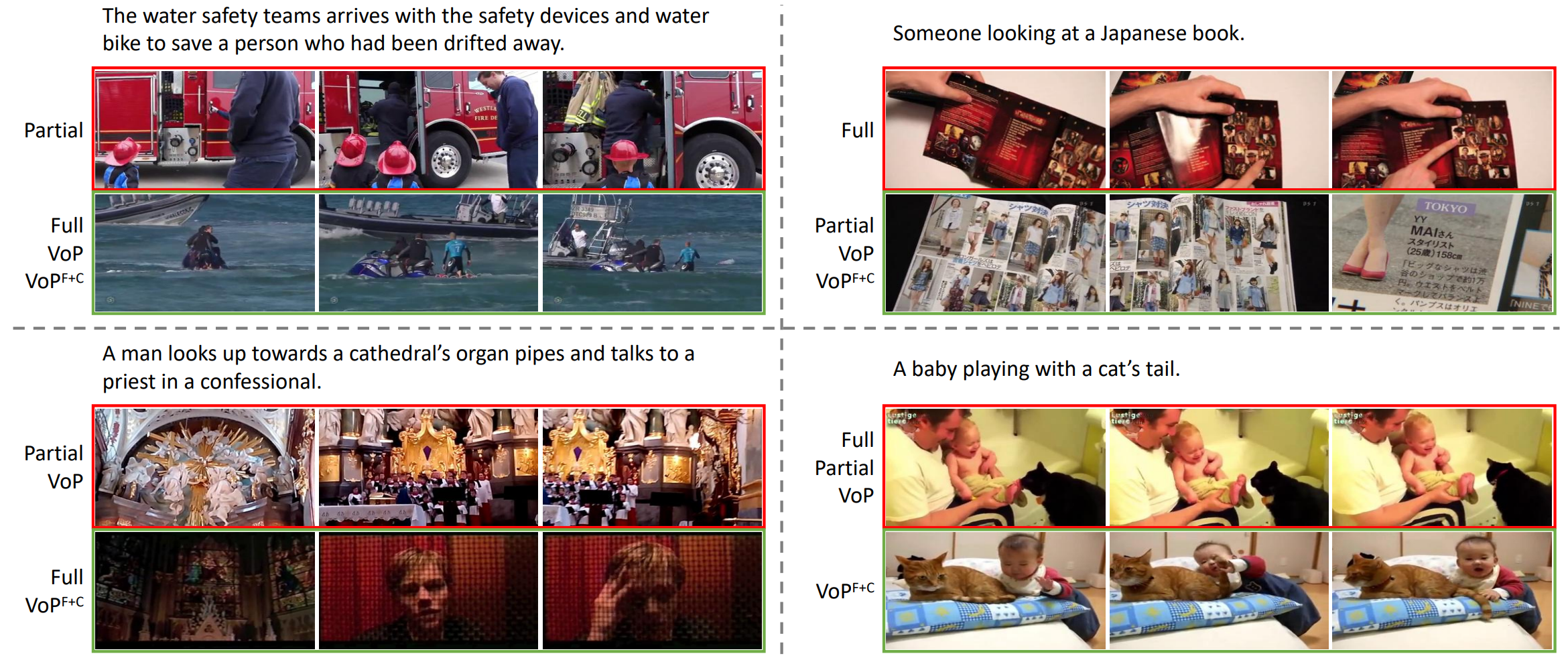
图4:部分方案的文本-视频检索结果展示
论文链接:https://arxiv.org/abs/2211.12764
代码链接:https://github.com/bighuang624/VoP
通过变分信息瓶颈微调优化弱监督下病理切片全场图分类
Task-specific Fine-tuning via Variational Information Bottleneck for
Weakly Supervised Pathology Whole Slide Image Classification
李虹林
杨林实验室2022级博士生
【背景知识】
数字病理学或显微图像分析已广泛用于诊断乳腺癌和宫颈癌等癌症。然而,病理科医生阅读具有千兆像素分辨率的病理切片全场图(Whole Slide Image, WSI)非常耗时,这迫切需要计算机辅助诊断。尽管计算机可以提高诊断速度,但WSI的高分辨率使得详尽的细胞级标注变得非常困难,另外当前的硬件几乎无法支持同时对WSI的所有细胞进行并行梯度回传,因此,对于这些实际问题,需要一种对标注依赖少且计算轻量的学习方案。
考虑到临床过程中,医生会对每个病人做出最终的诊断,因此获取病人级(单个WSI)的标签用于训练和评估是最实际的方案。由于WSI的癌变级别通常对应于所有细胞的最大病变级别,因此在训练时,可以通过构建AI模型以学习该假设。然而,由于算力限制和WSI的高分辨率,过去的方法都致力于设计WSI模型,而忽视了细胞级模型的表征能力,通常采用预训练的表征,如在细胞级别上进行自监督学习。然而,这种与任务无关的特征受到自监督代理目标的主导,例如对比学习可能会拉开同一类别内两个实例之间的距离,因此对于分类来说并不是最优,通常还需要利用少量的标注进一步微调。
【技术介绍】
我们设计了一种用于WSI分析的微调方案,将自然图像预训练或自监督得到的任务无关的表征转化为任务特定的表征以提升下游任务性能。受到信息瓶颈理论的启发,预训练在下游任务上存在差距,因此对WSI分析来说,微调是必要的。此外,考虑到WSI具有低秩、稀疏特性,我们利用了信息瓶颈的充分统计量和特征归因特性并采用了信息瓶颈的变分推断形式提出了一种解决微调和算力限制的方案,并在2个乳腺癌和1个宫颈癌数据上完成了实验验证。
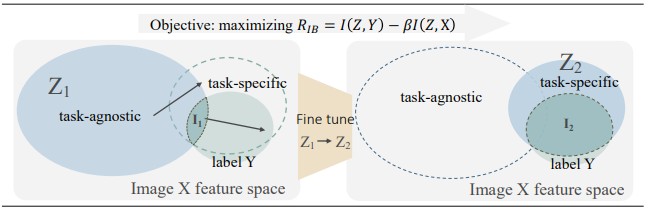
1. 我们提出了一个简单的WSI训练的代理任务,通过引入信息瓶颈模块,将一个WSI中数万个冗余的细胞实例精炼为最具有代表性的1,000个,于是基于梯度的训练并行计算成本减少了十倍以上。在对精炼的WSI进行分类学习过程中,我们发现由于病理WSI的低秩特性,仅存在一些微小的信息损失,并且精炼的WSI使得对细胞级的表征模型进行端到端训练成为可能。
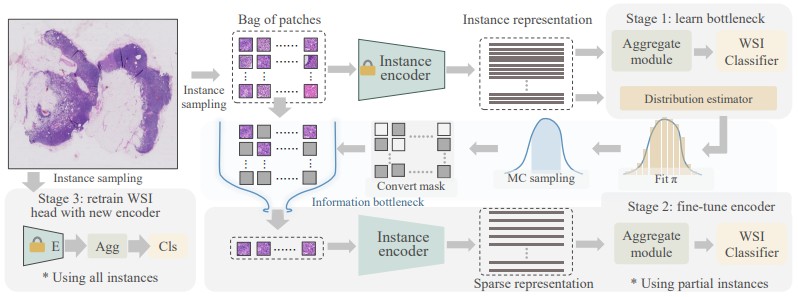
2. 精心设计的微调将自监督或预训练中的任务无关表征转化为任务特定的,这与最近的自然语言处理或自然图像自监督-微调方式类似,而且所提出的框架仅依赖于WSI级别的标注,总标注量可能可能不到1%的全细胞级标注,但实现相媲美的准确性。
3. 我们的微调方案可以与多种训练时数据增强方法结合使用,从而在具有域偏移(如切片染色)的各种真实或模拟数据集中实现更好的泛化效果。尽管对实际临床非常重要,但以前的工作往往忽视了这一点的验证。
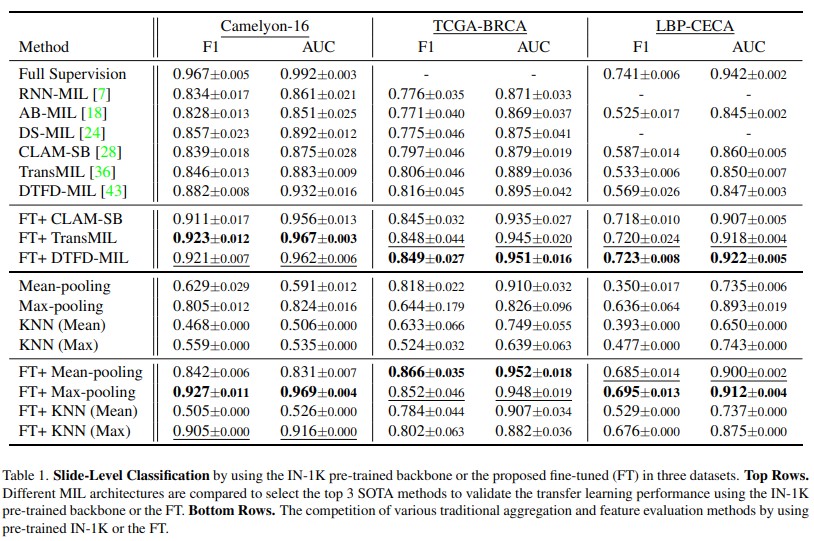
这些实验结果表明我们的方法同时提高了准确性和泛化能力,因此在临床应用中更具实用性。
论文链接:
代码链接:
https://github.com/invoker-LL/WSI-finetuning
EfficientSCI:基于密集连接神经网络和时空因式分解的大尺度视频单曝光压缩成像系统重建算法
EfficientSCI: Densely Connected Network with Space-time Factorization for Large-scale Video Snapshot Compressive Imaging
王理顺、曹淼
袁鑫实验室访问学生、袁鑫实验室2021级博士生
【背景知识】
人们通常采用高速相机来采集高速运动场景的视频,但是该方法需要较高的硬件成本和数据传输带宽。受压缩感知技术的启发,视频单曝光压缩成像系统提供了一种低成本、低带宽采集高速运动视频的解决方案。视频单曝光压缩成像系统由硬件编码器和软件解码器组成。硬件编码器采用多个不同的掩码来调制多张高速运动视频帧,然后通过一个低速相机在其单个曝光时间内采集一张压缩测量值,以此达到采用低速相机捕捉高速场景的目的。软件解码器将压缩测量值和对应的调制掩码作为输入,便可以重建出一系列高速运动视频帧。当前视频单曝光压缩成像系统的硬件编码器已经相对成熟,相比之下,尽管最近基于深度学习的软件解码器(即:重建算法)在大多数任务中取得了不错的重建效果,但由于其过高的模型复杂度和GPU的内存限制,当前的重建算法仍然面临以下挑战:(1)当前的重建算法仍然需要较高的计算成本,因而限制了视频单曝光压缩成像系统在资源受限设备(比如嵌入式设备和手机端等)上的应用部署;(2)现有的重建算法通常无法重建大尺度和高压缩比的彩色高速运动视频帧。
【技术介绍】
针对上述提到的视频单曝光压缩成像系统重建算法遇到的挑战,本文基于密集连接神经网络和时空因式分解机制提出了一个高效的视频单曝光压缩成像系统的重建算法(即:EfficientSCI),如图1所示。本文所提的重建算法优于之前所有基于深度学习的重建算法:在极大减少模型参数量的情况下,实现了更高的重建质量和更快的重建速度,如图3所示。本文有以下贡献点:
1. 本文提出了一个高效的视频单曝光压缩成像系统的重建算法。在大量仿真和真实测试集上的实验结果表明,本文所提算法达到了最好的重建质量,并且具备更好的实时性能;
2. 通过在单个残差模块中构建分层密集连接,设计出一个新颖的 ResDNet 模块,如图1(b)所示。该模块有效地降低了模型的计算复杂度,同时增强了模型的学习表示能力;
3. 基于时空因式分解机制,构建了卷积-Transformer混合模块(CFormer),如图2所示。该模块在空间域采用卷积操作以提取局部空间特征,在时间域采用Transformer用于建立长时序关联,从而有效地建立了重建视频帧之间的时空相关性。
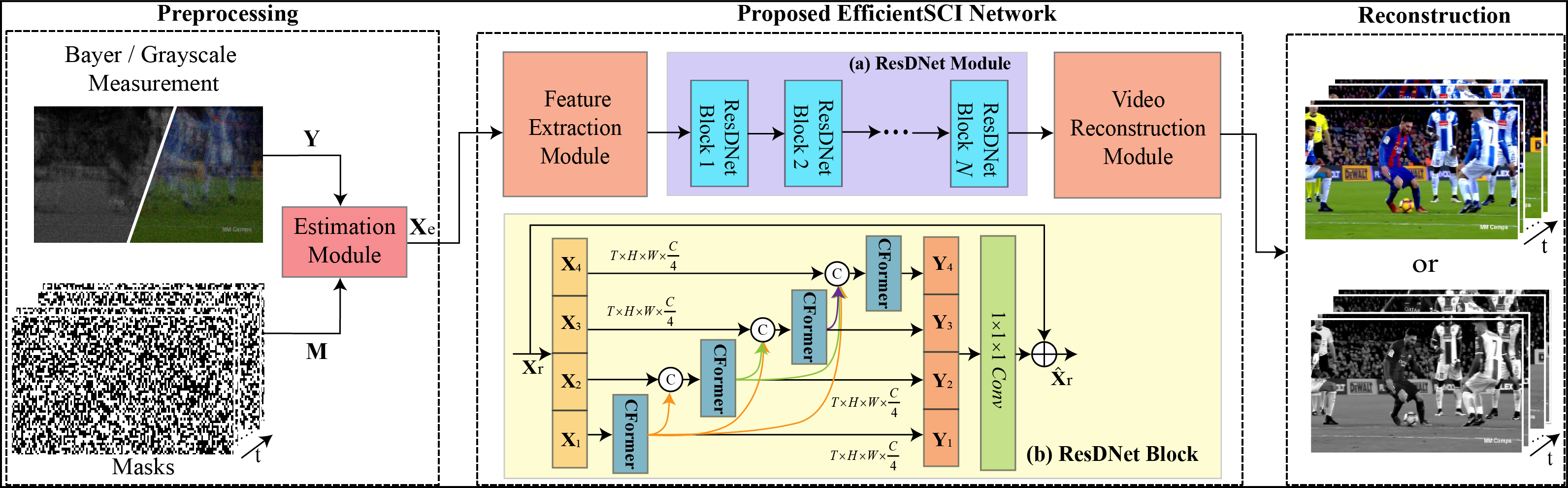
图1:EfficientSCI重建算法示意图
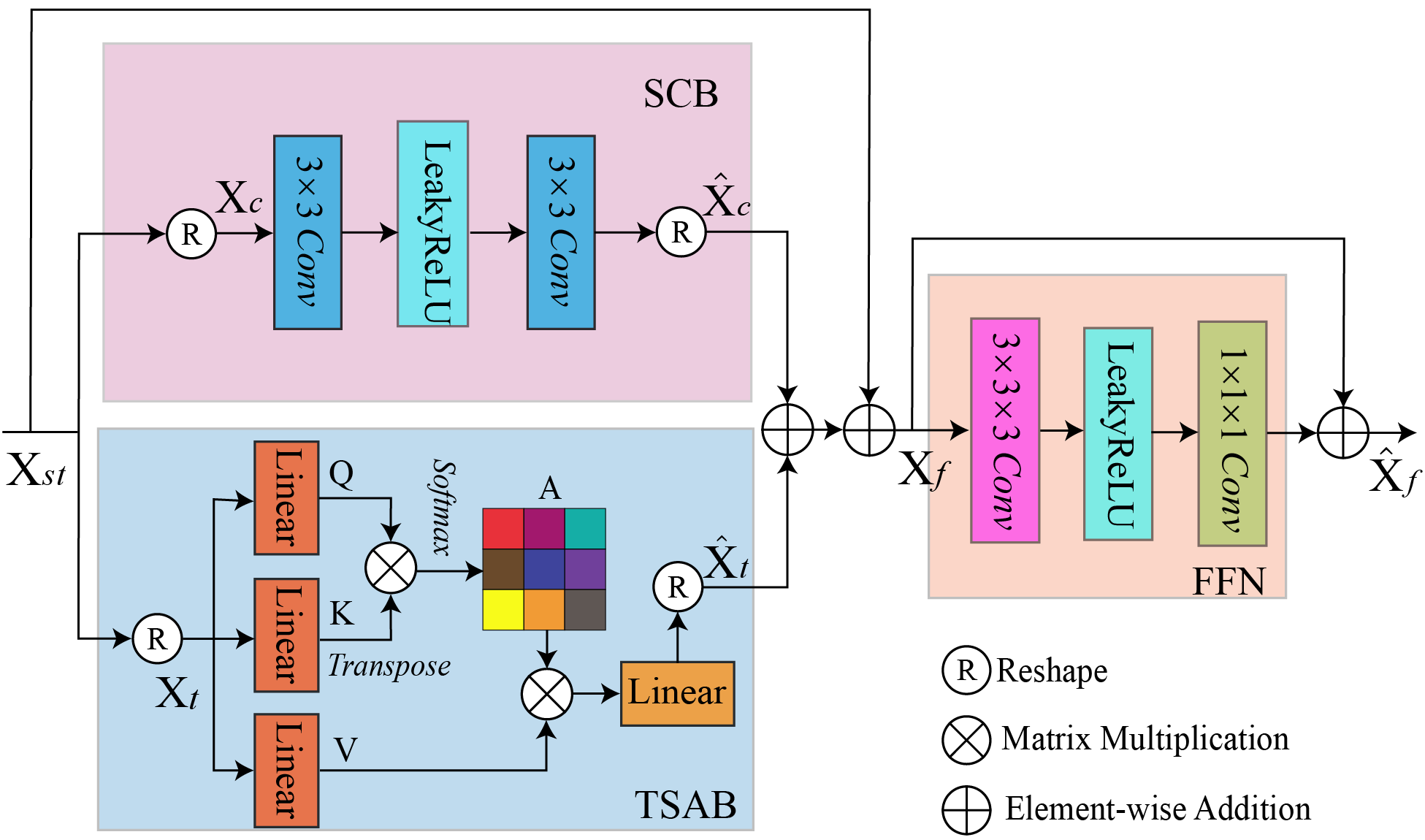
图2:CFormer模块结构图
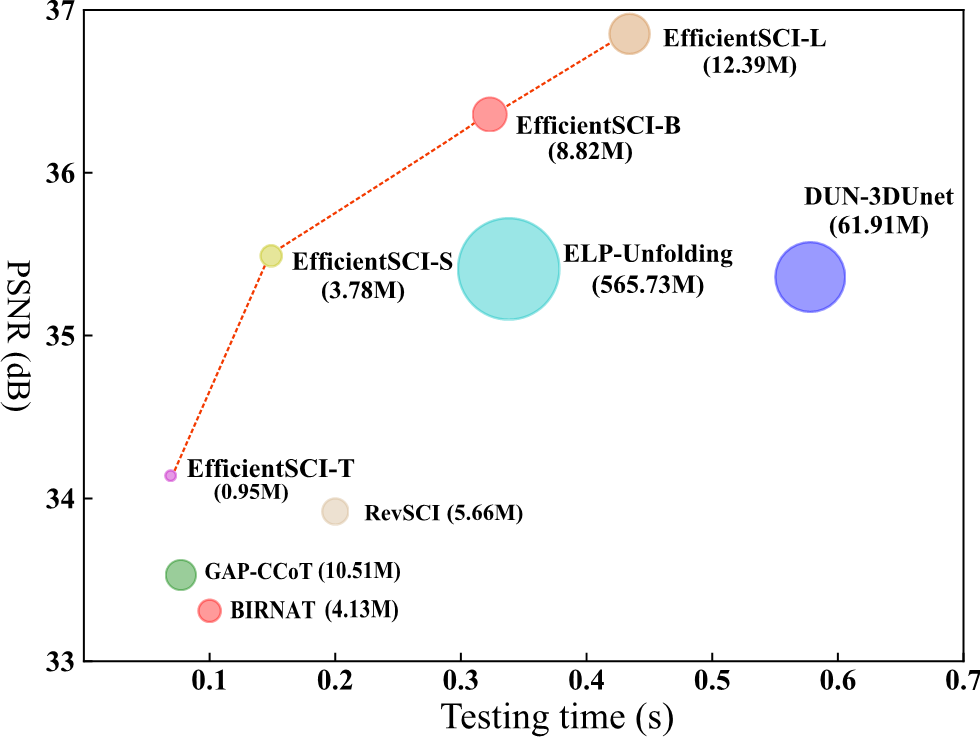
图3:EfficientSCI与主流基于深度学习的重建方法的性能对比
代码链接:https://github.com/ucaswangls/EfficientSCI
最新资讯
大学新闻
大学新闻
学术研究
人物故事
学术研究














