

搜索网站、位置和人员



电话: +86-(0)571-86886861 公共事务部
你是如何在不同的环境中行走的?
仔细想一下,当需要在坚硬的柏油路、柔软的沙地、崎岖的森林中走过相似的一段道路,你是不是会下意识走de“不一样”?在柏油路上,你能大踏步地往前走,无需担心地面不平而摔倒;在沙地中,你会步履轻巧一些来防止陷入其中;走在森林中崎岖的小道上,你会弯腰躲避横亘的枝丫,或是跃起跳过枯木。
对人类来说,根据不同环境调整自身行为以达到相同目的是如此简单。但对机器人而言,适应复杂环境是个众所周知的难题。
近期,人工智能顶级会议ICLR 2022公布了论文的收录结果,西湖大学工学院王东林课题组的最新成果“DARA: Dynamics-Aware Reward Augmentation in Offline Reinforcement Learning”入选,将这个问题的研究向前推进了一步。
ICLR全称为International Conference on Learning Representations(国际学习表征会议),于2013年由深度学习的两位“巨头”、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 牵头创办。根据2021年谷歌学术期刊和会议影响力榜单,举办仅九届的ICLR,在所有学科目录中排在第10位,与Science、Nature和Cell同处于TOP 10阵列。此项研究在西湖大学王东林老师的指导下(通讯作者),由19级博士生刘金鑫和科研助理张洪银共同完成(共同一作)。
该研究提出了一种自适应离线强化学习的新方法——环境动态的自适应奖励增强(DARA, Dynamics-Aware Reward Augmentation),提高了离线强化学习对不同“环境”的迁移适应能力,并将这一新算法部署到真实的机器狗上。
原文链接:https://openreview.net/pdf?id=9SDQB3b68K
研究始于强化学习中离线强化学习的一个难题——离线强化学习环境动态迁移问题,填补了离线强化学习领域的一个“空白”。
强化学习是机器学习的一种,它旨在让智能体(机器人)基于环境的反馈,进行一系列决策和行动,最终完成特定目标(或取得最大收益)。简要来说,这种方法训练智能体,让它像人类一样,通过与环境互动不断地试错,一步步达成最终任务。它可分为在线强化学习和离线强化学习。
在线强化学习,即保持学习中的智能体在线地和环境交互,即“边学习、边行动”。拿常见的应用场景自动驾驶举例,比如,智能体在学习过程中在线地控制车辆。处于学习中的(非专家)智能体面对一些未见过的“突发事件”时,若无法做出有效的决策,会导致一些安全相关的问题;另外,这种在线交互的时间成本是高昂的,需要在真实环境中不断地探索、收集数据。
离线强化学习,也就是不需要智能体在线的和环境交互,大大降低了这种“探索”的成本。此时,智能体不是和环境在线的试错,而是从预先收集的数据集(即离线数据集)中学习应对策略。同时,这些离线数据在现实生活中是常见的,例如我们在司机控制汽车的同时记录并保存司机的决策动作,并以此作为训练强化学习策略的离线数据。
离线强化学习优于在线强化学习的地方在于,离线强化学习不需要智能体和环境不断交互,大大降低了“探索”成本;但也存在明显的“短板”——严重依赖于离线数据集的数据量。伴随着数据量下降,离线强化学习算法的性能显著下降(图1)。
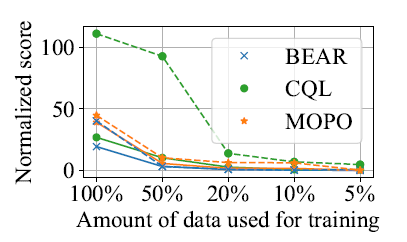
图1 各种离线强化学习方法性能随数据量的变化趋势
假如我们能获得的数据量就是那么有限,该如何是好?如何让算法摆脱对数据的依赖呢?研究团队想到了迁移学习。
面对我们需要执行任务的环境,离线强化学习假定我们对目标环境会预先好收集一堆数据,它构成了目标域离线数据集(目标数据集)。目标域描述了智能体的任务环境,我们的最终目的就是让智能体在目标域上做出最优的决策。
但目标数据集往往不足,因此我们转向另一个同类的离线数据集,称为源数据集,它构成了源域。所谓“迁移”,就是充分利用源数据集训练智能体,以克服目标域数据集不足导致训练的智能体性能下降的问题。
进一步,研究人员注意到,在这其中有一块未被探索的“空白地”。本研究的共同一作之一刘金鑫介绍说:“离线强化学习领域的域迁移的相关工作,主要关注目标域和源域的奖励函数(可以理解为目标)存在差异的情况,该怎么解决。而我们则着重考察源域和目标域之间的环境动态的差异——在现实环境中,这种差异是普遍存在的。”
此处的“环境动态”,你可以类比理解为训练机器人的一片“场地”。也就是说,当面对两个不一样的环境时,机器人要如何克服?拿本文走路的例子来比拟,比如,目标域是一片沙地,而源域是一段坚硬的柏油路,任务是径直走一千米。两者存在明显的地质差异,智能体如何学会把在平地上走路的训练经验,迁移到走沙地上,最终完成任务?
王东林课题组为此提出了一种新的离线强化学习的域自适应框架:环境动态的自适应奖励增强(DARA, Dynamics-Aware Reward Augmentation)。该方法通过修正源域数据中的奖励函数,使其修正项动态地适应源域和目标域的环境动态差异,进而减轻离线动态迁移的问题。换句话说,DARA就像是一个模型插件,插入到各种离线强化学习算法后,离线强化学习算法能够有效地克服环境差异、“适应”不同的环境。
 图2 DARA框架
图2 DARA框架
最后,研究人员将DARA带入虚拟环境和现实环境进行验证,进行了包括数值实验(图3)和实地环境四足机器人行走任务(图4)在内的实验。
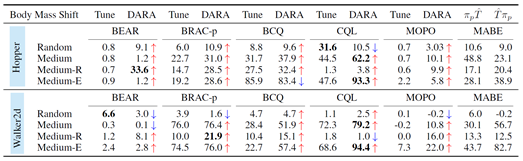
图3 标准数据集上的各种离线强化学习性能比较

图4 真实环境中四足机器人的性能比较(右侧为DARA的表现)
结果表明,DARA能够获得目标环境下的自适应策略,也就是能够克服源域和目标域两个环境之间的差异。而当存在足够的源域数据时,我们也就不需要目标域的大量数据了——换句话说,即便目标任务相关的数据量不足,离线强化学习也能完成“任务”了!
DARA的出现,补足了领域内的一块“空白地带”,正如ICLR2022一位审稿人所说:“这个工作是第一个聚焦离线强化学习动态迁移问题(即域自适应)的研究;这是一份很好的工作,可以激励研究者继续沿着这个方向开展研究。”
王东林团队进一步解释说,DARA是一种非常简单、轻巧、高效的算法,“部署”的成本和要求很低,并且它广泛兼容现有的离线强化学习的算法。也就是说,只要是离线强化学习的算法,只要它面临目标数据集不足、或收集数据成本比较高的困境,都可以通过插入DARA,来利用另一个数据集(即源数据集),完成最终任务。
现实中,DARA可适用的情景非常广泛。
比如,自动驾驶——较之让智能体在线控制车辆试错的高风险,我们可以收集司机在各种环境地形驾驶行为的离线数据,再加入DARA的“自适应”特性,让智能体学会在不同环境中该如何驾驶汽车:例如,在城市中让一批司机进行驾驶,然后将DARA代入算法中,让汽车能够在荒漠、雪地、沼泽等不同的环境中一样平稳驾驶……
再比如,医疗诊断——当医生所掌握的某位患者A的身体数据量有限时,我们可以借用另一位有同样疾病的患者B的诊断数据,来帮助生成适合患者A的药物服用建议;当然,这里需要应用DARA,来消弭两人身体状况的个体差异(比如其中一位患者存在其他潜在的疾病)……
又比如,网络购物推荐系统——如果系统中,某位用户的数据有限,系统可以智能地根据另一位顾客的过往购买信息,来给出商品推荐。再一次,DARA能够“消除”两个顾客的个体差异,诸如年龄、职业……
总而言之,本研究为离线强化学习中域自适应研究奠定了基础,指明了下一步的研究方向。同时,也为离线强化学习方法部署到真实机器人上起到了示范作用。另外,该方法也给缓解Sim2Real问题(即因仿真环境与真实环境存在的差异,导致仿真中训练好的控制策略在真实中表现不佳)提供了一个新的思路——从虚拟走入现实,也正是强化学习领域中长久存在的难题。
机器智能实验室
机器智能实验室(MiLAB)主要从事机器人学习领域的研究,深入研究如何用机器学习理论来提高真实机器人的行为智能,旨在赋予真实机器人行为灵活性、快速适应性和自主学习能力。MiLAB研究团队主要聚焦以下研究方向:1. 深度强化学习理论;2. 深度元学习理论;3. 机器人行为智能上的应用。具体研究深度强化学习理论以提高机器人的行为灵活性和行为自主学习的能力;研究深度元学习和小样本学习理论以提高机器人对于新任务的快速适应性;同时,也融合高效的数据挖掘方法和先进定位导航方法帮助机器人进行智能决策。实验室负责人王东林及团队目前发表国际学术论文百余篇,其中在MiLAB成立以后(2017年9月)已经发表包括ICLR、NeurIPS、KDD、IJCAI、AAAI、CVPR等人工智能顶会和国际期刊学术论文数十篇,申请专利十多项,研发特色足式机器人一款。详情见实验室网站:https://milab.westlake.edu.cn/。
实验室长期招聘岗位及要求
1. 招聘副研究员、助理研究员、博士后:要求具有深度学习、强化学习或机器人研究背景,协助指导博士生;
2. 招聘科研助理:计算机、通信、控制等相关专业硕士(或优秀本科生),要求具有深度学习或机器人研发经验,程序能力强;
3. 招聘软件开发工程师——机器人仿真方向:熟悉C++、Python编程;
4. 招聘实习生或访问学生:了解深度学习,要求程序能力或数学能力好。
请有意向者发简历到MiLAB实验室邮箱:mi_lab@westlake.edu.cn。
最新资讯
学术研究
大学新闻
我在西湖读博士














