

搜索网站、位置和人员



电话: +86-(0)571-85270350 公共事务部
今年双十一,阿里AI首次进行实时翻译直播,可提供214种语言的高质量翻译,一天可翻译3000亿个词语。并且无惧嘈杂环境、口音不标准及口语化语言风格等问题。
若干年前就有人预言,翻译或将和售货员一起失业。而今,从各种翻译神器到AI助力全球网购,我们似乎离那一天越来越近。
真的是这样吗?
“AI助力全球网购?应该没问题!”这是来自西湖大学文本智能实验室的回答。“不过,这不并说明机器就能彻底学会人类语言。这条路,其实还很遥远。”文本智能实验室PI张岳说。
半年前,他的研究团队曾经发起了一场“AI常识大赛”,目的就是为了搞清楚AI在语言学习上到底有多聪明。结果怎样?来看。
有趣的实验
当你拿起手机:“Hey Siri!今天天气怎么样?”她很快就能准确地告诉你所在城市的天气预报。
但若是把问题换成:“Hey Siri!今天应该穿怎样的外套?”接下去的对话很可能就跑偏了。
这些以聪明机灵、能说会道作为人设的人工智能,叫Chat Bot,比如苹果的Siri、百度的小度、淘宝的店小蜜……
你会发现,当你在百度地图中询问路况信息时,小度的专业回答让人不禁感叹智能时代近在眼前;但一旦切换到闲聊模式,几个回合就容易露出马脚,甚至容易犯下常识性的低级错误。
“现在自然语言处理的推动力量主要是靠深层神经网络的记忆能力,机器可以在背诵海量文本,然后再有针对性的题海战术训练的基础上,针对特定任务达到一定效果。然而,真正理解语言,可能还需要更好的处理常识和推理。”张岳说。
为了搞清楚“机器学习是否学会了常识和推理”,西湖大学张岳实验室今年开展了一系列研究,还面向全球发了“英雄帖”:
他们花了半年的时间制作上线了一个数据集,还在SemEval平台发起了一场“AI常识大赛”。来自世界各地的300多支队伍报名并下载了数据,最终40多支队伍带着自己的NLP(自然语言处理)模型到这个数据集上去“跑分”——
出题:
三种题型,考机器学习有没有常识
这场“AI常识大赛”是办在开源平台CodaLab上的,官方的名字叫Commonsense Validation and Explanation (ComVE) Challenge。参赛者会收到SemEval给出的三道考题,题型各不相同,难度依次进阶。
为了更便于理解AI在这些题目上的表现,我们对比了人和AI模型BERT做题的得分。
BERT是谷歌在2018年推出的一个通用的语言编码模型,曾在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩,甚至在部分指标上超越人类,不少从业者评价其为NLP领域带来了里程碑式的改变。我们现在接触到的很多人工智能对话系统、问答系统,都是将BERT这种强大的通用语言能力作为基础模型的。
第一道是判断题,基于常识判断对与错(Common sense Validation)。
SemEval给出两句话,让参赛者判断哪一句符合常识。举个例子:
Statement 1: He put an elephant into the fridge.(他把大象放进冰箱。)
Statement 2: He put a turkey into the fridge.(他把火鸡放进冰箱。)
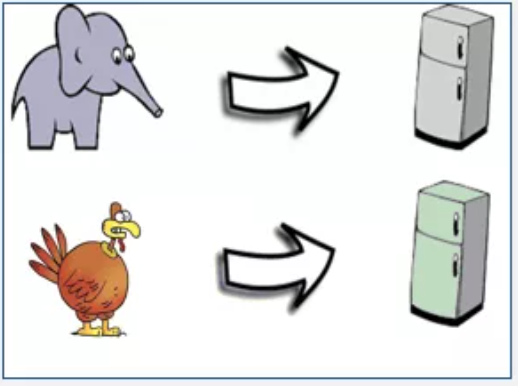
对于人来说,闭着眼睛都知道怎么做,但张岳团队还是找人测了一下。如果满分是100分,人的成绩是99.1,剩下0.9错在不专心审题。然后他们拿NLP模型BERT测了一次,在未进行任何针对性训练的情况下,成绩只有70.1分,刚过及格线。
第二道是选择题,在判断对错的基础上,进一步考察是否知道“为什么”(Explanation)。
同样是“大象放进冰箱”,参赛者需要在三个选项中,选择一个解释为什么大象不能被放进冰箱。
A: An elephant is much bigger than a fridge. (因为大象比冰箱大太多。)
B: Elephants are usually white while fridges are usually white. (因为大象通常是白色的,而冰箱通常也是白色的。)
C:An elephant cannot eat a fridge.(因为大象不能吃掉冰箱。)
如果说判断题还有一半机率蒙对,到了选择题,人工智能的分数更低了,BERT在未经训练的情况下只拿了45.6分,不及格。
继续加难度。第三道是简答题,也就是说不再有选项,AI需要自己组织语言回答问题(Generation)。
还是“大象放进冰箱”的例子,要求回答为什么“他把大象放进冰箱”是不符合常识的?以下三个是参考答案:
Reason1: An elephant is much bigger than a fridge. (因为大象比冰箱大太多。)
Reason2: A fridge is much smaller than an elephant. (因为冰箱比大象小太多。)
Reason3: Most of fridges aren't large enough to contain an elephant.(因为冰箱还不够大到能装下大象。)
“一改成问答,像BERT这样的模型如果未经训练,就不知道怎么回答了。”张岳说,“SemEval的测试结果很有意思,看起来BERT实际上是知道一些常识的,但这种常识非常有限,对常识的运用也远远达不到人类的水平。”
评测:
40多个参赛模型,最高能拿95分
通过上面实验,我们看到人类智能与未经特别训练的人工智能,在常识问题上的实力对比还是比较悬殊的。然而,人工智能的强大之处在于,它具备高效率的学习能力。换句话说,它是可以被训练的。
为此,张岳实验室设计了几个训练集,用数千条类似的常识数据去训练BERT。学习之后的BERT再去做同样的测试题,第一道判断题可以做到90.2分,第二道选择题可以做到92.4分,成绩飞速提升。
在他们发起的“AI常识大赛”上,来自世界各地的自然语言处理团队来挑战SemEval的常识题库。其中不乏来自哈尔滨工业大学、中科院、香港中文大学、美国密歇根大学、新加坡南洋理工大学、东京工业大学等名校的团队,也有来自三星研究院、百度研究院的企业界代表。
他们带着经过训练的NLP模型试着在SemEval上“跑分”,第一题和第二题满分100分,在针对性训练的情况下,表现最好的队伍能拿到95分;但第三题简答还有待提高,满分3分,最高只有2.1左右,相当于100分里拿70分。
这种有针对性的训练,有点类似“题海战术”的模式。背诵了大量文本的预训练模型,在有针对性地做了数千道选择题以后,学会了如何应对类似问题。但是从问答题的不良表现来看,死记硬背的题海战术还存在适应能力的不足。
这项“AI常识大赛”的主导者西湖大学博士研究生王存翔同学,进一步分析了模型在训练之后能够在第一题和第二题做得更准确的原因,发现这并不完全是因为模型学到了如何使用常识解题,而是在很大程度上因为模型“投机取巧”地利用了答案选项中长度、否定词、答案与题目的匹配程度以及答案与训练题库中答案的匹配程度等表面特征。
另一位博士研究生崔乐阳、科研助理黄丹丹、访问学生周旭辉则进一步研究了BERT中的常识信息,探讨了它的局限[2]。
“NLP的从业者都知道BERT很强大,但它到底是如何学习的,它在死记硬背的过程中有没有学会常识,学会多少常识,还很少有人去细究。”张岳说,NLP发展到今天,特别是在以BERT为代表的技术推出后,已经能够帮助人类完成很多机械式的任务,但它依然存在很多局限,而这种局限往往出现在人最不可能犯错的常识领域。
“事实上,记忆能力只是人类学习的一部分。现在的机器学习算法有很强的记忆能力,能够从上千万对中英文对照的句子中学会机器翻译,但人类不可能从10,000,000对对照的句子中,学会如何把一种语言翻译成另一种语言。在人类的学习过程中,是经过了逻辑推理,化繁为简,把复杂现象拆分成容易记住的基本单元,循序渐进地理解的。在这个过程中,也包含了大量的背景知识和常识。这或是当前神经网络方法的最大不足。”张岳说。
崔乐阳在微软亚洲研究院周明课题组实习时也做了一个数据集,同样是从常识的角度出发考察对话系统是否具备通过上下文推断情境的能力。比如身在北京的甲跟身在伦敦的乙对话,AI能否具备“时差”的常识[3]。
刘健则号召实验室的同学们把公务员考试中的逻辑题翻译成英文做成数据集[4],博士研究生刘汉蒙把美国警察考试等逻辑题变为文本蕴含的形式[5]。在这些数据集上,BERT一败涂地。
呼吁:
机器学习靠题海战术走不远
“像人一样去学习”,是张岳实验室正在追求的一种机器学习方式。
他们从评价的方式、探究的方式两个角度,研究了BERT这类极大推进了自然语言处理领域进步的技术,到底在多大程度上捕捉了人类的常识。“假设BERT死记硬背了1万条信息,理解了其中300~400条,它所具备的常识可能只到这个水平,其他都是生搬硬套的,所以它会出现问题。”张岳解释,相当于一个学生通过题海战术,多多少少能总结出来一些经验,“但BERT总结出来的这些经验有多少是跟人类常识相符的,我们想探究一下。”
身处自然语言处理基础研究前沿的张岳,看到了死记硬背式的训练所带来的模型能力提升,也看到了这种提升给从业者带来的兴奋与刺激,但他更想呼吁大家,更多关注如何让机器学会常识、学会推理、学会人类学习与思考问题的方式。
为了让机器真正像人一样学习,追求人类学习方式的AI算法,我们走了很多条路,最近也做了一系列工作。
我们总结了几条人类学习的方法,比如自左向右去理解文本,比如可以多个不同类型的任务(理解和总结)一起学习,比如可以利用知识去解决问题……我们还和西湖大学生命科学学院的孙一老师合作,研究神经系统认知到底是怎么回事。
我们朝着研究常识、研究逻辑的方向推进自然语言处理,给机器以人的思维。
其实,早在上世纪五十年代到九十年代,逻辑推理是人工智能发展的重中之重,当时大家非常重视推理。举个例子,在那个年代影响很大的两个编程语言,Prolog和LISP,都是通过逻辑去做推理运算的。
非常遗憾的是,当时这些逻辑推理都是通过符号系统来做运算的,自然语言处理的能力还跟不上,最终逐渐走向失败。
但现在不一样,自然语言处理的能力已经有了极大提升,语言逻辑应该被再次摆到桌面上来。
行百里者半九十。不论是自然语言处理这一领域也好,还是人工智能行业来讲,要走好将来的路,就一定要想办法克服死记硬背的瓶颈。我们的眼睛不要盯着任务式的评测指标,做机器翻译的总在拼BLEU的分数,做文本摘要的总在拼ROUGE,是时间停下来反思一下:
我们的模型是不是真正像人一样融会贯通地在学习。
(附录)西湖大学张岳实验室2020年相关文章链接
[1] Cunxiang Wang, Shuailong Liang, Yili Jin, Yilong Wang, Xiaodan Zhu, and Yue Zhang. 2020. SemEval-2020 task 4: Commonsense validation and explanation. In Proceedings of The 14th International Workshop on Semantic Evaluation. Association for Computational Linguistics.[ http://arxiv.org/abs/2007.00236]
[2] Xuhui Zhou,Yue Zhang, Leyang Cui, Dandan Huang. Evaluating Commonsense in Pre-trained Language Models. In Proceedings of Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, USA, February. [ https://www.aaai.org/Papers/AAAI/2020GB/AAAI-ZhouX.8401.pdf]
[3] Leyang Cui, Yu Wu, Shujie Liu, Yue Zhang and Ming Zhou. 2020. MuTual: A Dataset for Multi-Turn Dialogue Reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). Seattle, Washington, USA,July. [https://frcchang.github.io/pub/acl20.cui.pdf]
[4] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Hang, Yile Wang, Yue Zhang.2020 LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning . In Proceddings of IJCAI 2020. Yokohama, July. [https://frcchang.github.io/pub/ijcai20.liu.pdf]
[5] Hanmeng Liu, Leyang Cui, Jian Liu, Yue Zhang. 2021. Natural Language Inference in Context - Investigating Contextual Reasoning over Long Texts. In Proceddings of AAAI 2021. A Virtual Conference, February. [https://frcchang.github.io/pub/aaai21.liu.pdf]
最新资讯
学术研究
学术研究
学术研究
学术研究














